dominanza diagonale. Sistemi a dominanza diagonale
UNIVERSITÀ STATALE DI SAN PIETROBURGO
Facoltà di Matematica Applicata - Processi di controllo
A. P. IVANOV
LABORATORIO DI METODI NUMERICI
SOLUZIONE DI SISTEMI DI EQUAZIONI ALGEBRICHE LINEARI
Linee guida
San Pietroburgo
CAPITOLO 1. INFORMAZIONI DI SUPPORTO
A guida metodologica vengono fornite la classificazione dei metodi per la risoluzione di SLAE e gli algoritmi per la loro applicazione. I metodi sono presentati in una forma che ne consente l'uso senza riferimento ad altre fonti. Si assume che la matrice del sistema sia non singolare, cioè det A 6= 0.
§uno. Norme di vettori e matrici
Ricordiamo che uno spazio lineare Ω di elementi x si dice normalizzato se contiene una funzione k · kΩ , che è definita per tutti gli elementi dello spazio Ω e soddisfa le seguenti condizioni:
1. kxkΩ ≥ 0, e kxkΩ = 0 x = 0Ω ;
2. kλxkΩ = |λ| kxkΩ ;
3. kx + ykΩ ≤ kxkΩ + kykΩ .
In futuro, accetteremo di denotare vettori con lettere latine minuscole e li considereremo vettori colonna, indicheremo matrici con lettere latine maiuscole e indicheremo quantità scalari con lettere greche (mantenendo le designazioni per numeri interi dietro le lettere io, j, k, l, m, n).
Le norme vettoriali più comunemente utilizzate includono quanto segue:
|xi|; |
|
1. kxk1 = |
|
2. kxk2 = ux2 ; t
3. kxk∞ = maxi |xi |.
Si noti che tutte le norme nello spazio Rn sono equivalenti, cioè due norme qualsiasi kxki e kxkj sono correlate da:
αij kxkj ≤ kxki ≤ βij kxkj ,
k k ≤ k k ≤ ˜ k k
α˜ ij x io x j β ij x io,
inoltre, αij , βij , α˜ij , βij non dipendono da x. Inoltre, in uno spazio a dimensione finita, due norme qualsiasi sono equivalenti.
Lo spazio delle matrici con le operazioni naturalmente introdotte di addizione e moltiplicazione per un numero forma uno spazio lineare in cui la nozione di norma può essere introdotta in molti modi. Tuttavia, le cosiddette norme subordinate sono spesso considerate, ad es. norme legate alle norme dei vettori dalle relazioni:
Segnando le norme subordinate delle matrici con gli stessi indici delle corrispondenti norme dei vettori, possiamo stabilirlo
kk1 |
|aij|; kAk2 |
k∞ |
|||||||||||||
(AT A); |
|||||||||||||||
Qui, λi (AT A) denota l'autovalore della matrice AT A, dove AT è la matrice trasposta in A. Oltre alle tre proprietà principali della norma sopra menzionate, ne notiamo altre due:
kABk ≤ kAk kBk,
kAxk ≤ kAk kxk,
inoltre, nell'ultima disuguaglianza, la norma matriciale è subordinata alla corrispondente norma vettoriale. Conveniamo di utilizzare in quanto segue solo le norme delle matrici subordinate alle norme dei vettori. Si noti che per tali norme vale l'uguaglianza: se E è la matrice identità, allora kEk = 1, .
§2. Matrici a dominanza diagonale
Definizione 2.1. Una matrice A con elementi (aij )n i,j=1 si dice matrice a dominanza diagonale (valori δ) se le disuguaglianze
|ai | − |aij| ≥ δ > 0, io = 1, n .
§3. Matrici definite positive
Definizione 3.1. Verrà chiamata la matrice simmetrica A
definito positivo se la forma quadratica xT Ax con questa matrice assume solo valori positivi per qualsiasi vettore x 6= 0.
Il criterio per la definitezza positiva di una matrice può essere la positività dei suoi autovalori o la positività dei suoi minori principali.
§quattro. Numero di condizione di SLAE
Quando si risolve qualsiasi problema, come è noto, ci sono tre tipi di errori: errore fatale, errore metodologico ed errore di arrotondamento. Consideriamo l'influenza dell'errore fatale dei dati iniziali sulla soluzione dello SLAE, trascurando l'errore di arrotondamento e tenendo conto dell'assenza di un errore metodologico.
la matrice A è nota esattamente e il lato destro b contiene un errore ineliminabile δb.
Allora per l'errore relativo della soluzione kδxk/kxk
è facile ottenere un preventivo: |
|||||||
dove ν(A) = kAkkA−1k.
Il numero ν(A) è detto numero di condizione del sistema (4.1) (o matrice A). Risulta che sempre ν(A) ≥ 1 per ogni matrice A. Poiché il valore del numero di condizione dipende dalla scelta della norma della matrice, quando si sceglie una norma specifica, indicizzeremo ν(A) , rispettivamente: ν1 ( A), ν2 (A) o ν ∞(A).
Nel caso ν(A) 1, il sistema (4.1) o la matrice A si dice mal condizionato. In questo caso, come segue dalla stima

(4.2) , l'errore nella soluzione del sistema (4.1) può risultare inaccettabilmente grande. Il concetto di accettabilità o inaccettabilità di un errore è determinato dalla formulazione del problema.
Per una matrice con dominanza diagonale, è facile ottenere una stima superiore del suo numero di condizione. Si verifica
Teorema 4.1. Sia A una matrice con dominanza diagonale di δ > 0. Allora è non singolare e ν∞ (A) ≤ kAk∞ /δ.
§5. Un esempio di sistema mal condizionato.
Considera SLAE (4.1) , in cui
−1 |
− 1 . . . |
−1 |
−1 |
|||||||||
−1 |
.. . |
|||||||||||
−1 |
||||||||||||
Questo sistema ha un'unica soluzione x = (0, 0, . . . , 0, 1)T . Sia il lato destro del sistema contenga l'errore δb = (0, 0, . . . , 0, ε), ε > 0. Allora
δxn = ε, δxn−1 = ε, δxn−2 = 2 ε, δxn−k = 2 k−1 ε, . . . , δx1 = 2n−2ε.
k∞ = |
2n−2ε, |
k∞ |
k∞ |
|||||||||||||
kk∞ |
||||||||||||||||
Di conseguenza,
ν∞ (A) ≥ kδxk ∞ : kδbk ∞ = 2n−2 . kxk ∞ kbk ∞
Poiché kAk∞ = n, allora kA−1 k∞ ≥ n−1 2 n−2 , sebbene det(A−1 ) = (det A)−1 = 1. Sia, ad esempio, n = 102. Allora ν( A ) ≥ 2100 > 1030 . Inoltre, anche se ε = 10−15 otteniamo kδxk∞ > 1015 . E questo non lo è
Definizione.
Chiamiamo sistema un sistema con dominanza diagonale di riga se gli elementi della matricesoddisfa le disuguaglianze:
 ,
,

Le disuguaglianze significano che in ogni riga della matrice  si evidenzia l'elemento diagonale: il suo modulo è maggiore della somma dei moduli di tutti gli altri elementi della stessa riga.
si evidenzia l'elemento diagonale: il suo modulo è maggiore della somma dei moduli di tutti gli altri elementi della stessa riga.
Teorema
Un sistema con dominanza diagonale è sempre risolvibile e, inoltre, unico.
Considera il corrispondente sistema omogeneo:
 ,
,

Supponiamo che abbia una soluzione non banale 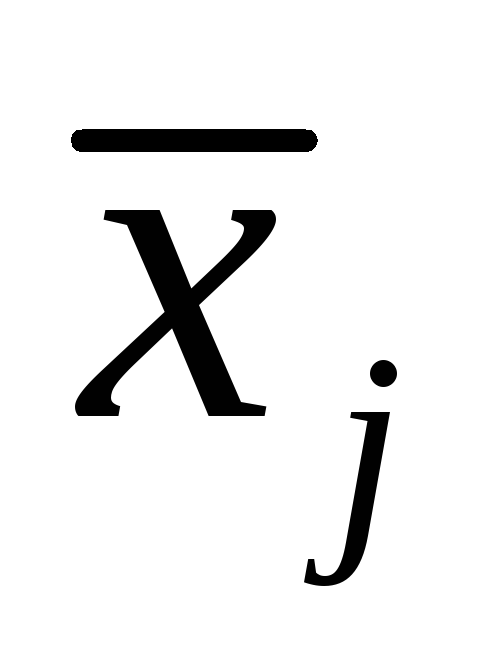 , Sia la componente di questa soluzione, che ha il modulo più grande, corrispondere all'indice
, Sia la componente di questa soluzione, che ha il modulo più grande, corrispondere all'indice  , cioè.
, cioè.
 ,
, ,
,
 .
.
Scriviamo  esima equazione del sistema nella forma
esima equazione del sistema nella forma

e prendi il modulo di entrambi i membri di questa uguaglianza. Di conseguenza, otteniamo:
 .
.
Ridurre la disuguaglianza di un fattore  , che, secondo, non è uguale a zero, arriviamo a una contraddizione con la disuguaglianza che esprime dominanza diagonale. La contraddizione che ne risulta ci permette di affermare coerentemente tre affermazioni:
, che, secondo, non è uguale a zero, arriviamo a una contraddizione con la disuguaglianza che esprime dominanza diagonale. La contraddizione che ne risulta ci permette di affermare coerentemente tre affermazioni:

L'ultimo di essi significa che la dimostrazione del teorema è completa.
Sistemi a matrice tridiagonale. Metodo di spazzata.
Quando si risolvono molti problemi, si ha a che fare con sistemi di equazioni lineari della forma:
, ,
,
 ,
, ,
,
dove coefficienti  , lati destro
, lati destro 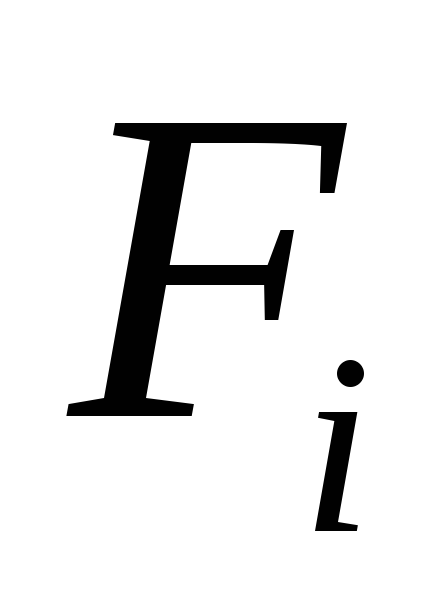
 noto insieme ai numeri
noto insieme ai numeri  e
e  . Le relazioni aggiuntive sono spesso chiamate condizioni al contorno per il sistema. In molti casi, possono avere un aspetto più complesso. Per esempio:
. Le relazioni aggiuntive sono spesso chiamate condizioni al contorno per il sistema. In molti casi, possono avere un aspetto più complesso. Per esempio:
 ;
;
 ,
,
dove  sono dati i numeri. Tuttavia, per non complicare la presentazione, ci limitiamo alla forma più semplice di condizioni aggiuntive.
sono dati i numeri. Tuttavia, per non complicare la presentazione, ci limitiamo alla forma più semplice di condizioni aggiuntive.
Approfittando del fatto che i valori  e
e  dato, riscriviamo il sistema nella forma:
dato, riscriviamo il sistema nella forma:

La matrice di questo sistema ha una struttura tridiagonale:

Ciò semplifica notevolmente la soluzione del sistema grazie a un metodo speciale chiamato metodo sweep.
Il metodo si basa sul presupposto che le incognite desiderate  e
e  legati dalla relazione di ricorrenza
legati dalla relazione di ricorrenza
 ,
, .
.
Qui le quantità  ,
, , detti coefficienti di sweep, devono essere determinati in base alle condizioni del problema, . Tale procedura, infatti, significa sostituire la definizione diretta delle incognite
, detti coefficienti di sweep, devono essere determinati in base alle condizioni del problema, . Tale procedura, infatti, significa sostituire la definizione diretta delle incognite  il compito di determinare i coefficienti di sweep con il successivo calcolo delle grandezze
il compito di determinare i coefficienti di sweep con il successivo calcolo delle grandezze  .
.
Per implementare il programma descritto, esprimiamo utilizzando la relazione  attraverso
attraverso  :
:
e sostituire  e
e 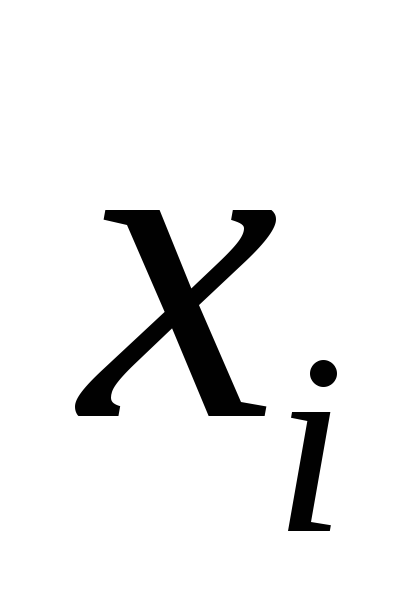 , espresso attraverso
, espresso attraverso  , nelle equazioni originali. Di conseguenza, otteniamo:
, nelle equazioni originali. Di conseguenza, otteniamo:
 .
.
Le ultime relazioni saranno certamente soddisfatte e, inoltre, indipendentemente dalla soluzione, se è richiesto che a  si sono verificate le uguaglianze:
si sono verificate le uguaglianze:

Da qui seguono le relazioni ricorsive per i coefficienti di sweep:
 ,
, ,
, .
.
Condizione al contorno sinistro  e rapporto
e rapporto  sono consistenti se poniamo
sono consistenti se poniamo
 .
.
Altri valori dei coefficienti di sweep  e
e  troviamo da, con cui e completiamo la fase di calcolo dei coefficienti di sweep.
troviamo da, con cui e completiamo la fase di calcolo dei coefficienti di sweep.
 .
.
Da qui puoi trovare il resto delle incognite  nel processo di scansione all'indietro utilizzando una formula ricorsiva.
nel processo di scansione all'indietro utilizzando una formula ricorsiva.
Il numero di operazioni necessarie per risolvere un sistema generale utilizzando il metodo gaussiano aumenta con l'aumentare 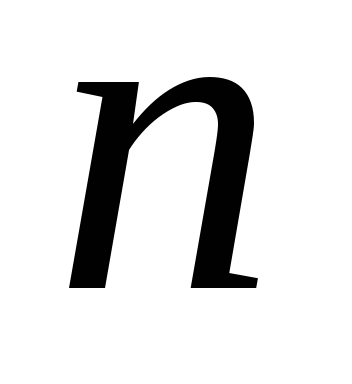 proporzionalmente
proporzionalmente  . Il metodo di sweep è ridotto a due cicli: prima si calcolano i coefficienti di sweep utilizzando le formule, quindi, utilizzandoli, si trovano i componenti della soluzione del sistema utilizzando le formule ricorrenti
. Il metodo di sweep è ridotto a due cicli: prima si calcolano i coefficienti di sweep utilizzando le formule, quindi, utilizzandoli, si trovano i componenti della soluzione del sistema utilizzando le formule ricorrenti  . Ciò significa che all'aumentare delle dimensioni del sistema, il numero di operazioni aritmetiche crescerà proporzionalmente
. Ciò significa che all'aumentare delle dimensioni del sistema, il numero di operazioni aritmetiche crescerà proporzionalmente  , ma no
, ma no  . Pertanto, il metodo sweep nell'ambito della sua possibile applicazione è significativamente più economico. A ciò va aggiunta la particolare semplicità della sua implementazione software su un computer.
. Pertanto, il metodo sweep nell'ambito della sua possibile applicazione è significativamente più economico. A ciò va aggiunta la particolare semplicità della sua implementazione software su un computer.
In molti problemi applicati che portano a SLAE con una matrice tridiagonale, i suoi coefficienti soddisfano le disuguaglianze:
 ,
,
che esprimono la proprietà della dominanza diagonale. In particolare, incontreremo tali sistemi nel terzo e nel quinto capitolo.
Secondo il teorema della sezione precedente, la soluzione di tali sistemi esiste sempre ed è unica. Hanno anche un'affermazione importante per il calcolo effettivo della soluzione usando il metodo sweep.
Lemma
Se per un sistema con matrice tridiagonale è soddisfatta la condizione di dominanza diagonale, allora i coefficienti di sweep soddisfano le disuguaglianze:
 .
.
Svolgiamo la dimostrazione per induzione. Secondo  , io mangio
, io mangio  l'affermazione del lemma è vera. Supponiamo ora che sia vero per
l'affermazione del lemma è vera. Supponiamo ora che sia vero per  e considera
e considera  :
:
 .
.
Quindi l'induzione da  a
a 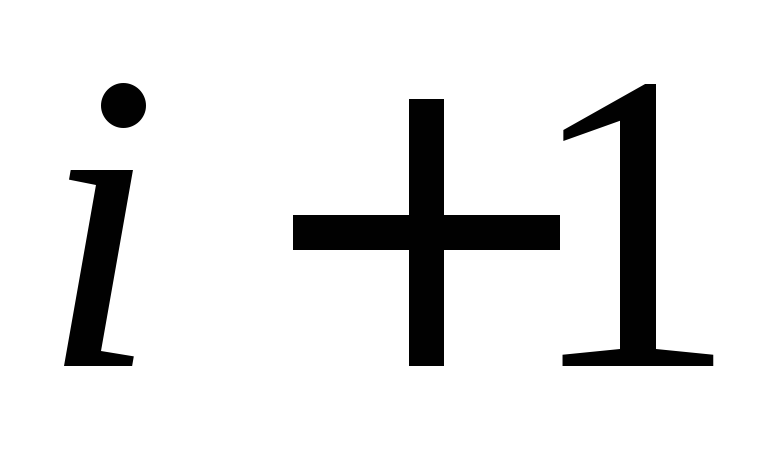 giustificato, che completa la dimostrazione del lemma.
giustificato, che completa la dimostrazione del lemma.
Disuguaglianza per i coefficienti di sweep  rende la corsa stabile. Supponiamo infatti che la componente di soluzione
rende la corsa stabile. Supponiamo infatti che la componente di soluzione  come risultato della procedura di arrotondamento viene calcolato con qualche errore. Quindi quando si calcola il componente successivo
come risultato della procedura di arrotondamento viene calcolato con qualche errore. Quindi quando si calcola il componente successivo  secondo la formula ricorsiva, questo errore, dovuto alla disuguaglianza, non aumenterà.
secondo la formula ricorsiva, questo errore, dovuto alla disuguaglianza, non aumenterà.
NON DEGENERITA' DELLE MATRICI E PROPRIETA' DI DOMINANZA DIAGONALE1
L. Cvetkovich, V. Kostic e L.A. Più corrotto
Cvetkovic Liliana - Professore, Dipartimento di Matematica e Informatica, Facoltà di Scienze, Università di Novi Sad, Serbia, Obradovica 4, Novi Sad, Serbia, 21000, e-mail: [e-mail protetta]
Kostic Vladimir - Assistente Professore, Dottore, Dipartimento di Matematica e Informatica, Facoltà di Scienze, Università di Novi Sad, Serbia, Obradovica 4, 21000, Novi Sad, Serbia, email: [e-mail protetta]
Krukier Lev Abramovich - Dottore in scienze fisiche e matematiche, professore, capo del dipartimento di informatica ad alte prestazioni e tecnologie dell'informazione e della comunicazione, direttore del Centro regionale della Russia meridionale per l'informatizzazione del sud università federale, Stachki Ave. 200/1, edificio. 2, Rostov sul Don, 344090, e-mail: [e-mail protetta] ru.
Cvetkovic Ljiljana - Professore, Dipartimento di Matematica e Informatica, Facoltà di Scienze, Università di Novi Sad, Serbia, D. Obradovica 4, Novi Sad, Serbia, 21000, e-mail: [e-mail protetta]
Kostic Vladimir - Assistant Professor, Dipartimento di Matematica e Informatica, Facoltà di Scienze, Università di Novi Sad, Serbia, D. Obradovica 4, Novi Sad, Serbia, 21000, e-mail: [e-mail protetta]
Krukier Lev Abramovich - Dottore in scienze fisiche e matematiche, professore, capo del dipartimento di calcolo ad alte prestazioni e tecnologie dell'informazione e della comunicazione, direttore del centro informatico dell'Università federale meridionale, Stachki Ave, 200/1, bild. 2, Rostov sul Don, Russia, 344090, e-mail: [e-mail protetta] ru.
La dominanza diagonale nella matrice è condizione semplice, garantendone la non degenerazione. Le proprietà della matrice che generalizzano la nozione di dominanza diagonale sono sempre molto richieste. Sono considerate come condizioni di tipo a dominanza diagonale e aiutano a definire sottoclassi di matrici (come le matrici H) che rimangono non degenerate in queste condizioni. In questo articolo costruiamo nuove classi di matrici non singolari che conservano i vantaggi della dominanza diagonale ma rimangono al di fuori della classe delle matrici H. Queste proprietà sono particolarmente convenienti perché molte applicazioni portano a matrici di questa classe e la teoria della non degenerazione di matrici che non sono matrici H può ora essere estesa.
Parole chiave: dominanza diagonale, non degenerazione, ridimensionamento.
Mentre le condizioni semplici che assicurano la non singolarità delle matrici sono sempre ben accette, molte delle quali che possono essere considerate come un tipo di dominanza diagonale tendono a produrre sottoclassi di ben note matrici H. In questo articolo costruiamo una nuova classe di matrici non singolari che conservano l'utilità della dominanza diagonale, ma sono in relazione generale con la classe delle matrici H. Questa proprietà è particolarmente favorevole, poiché molte applicazioni che derivano dalla teoria della matrice H possono ora essere estese.
Parole chiave: dominanza diagonale, non singolarità, tecnica di scaling.
La soluzione numerica dei problemi ai limiti della fisica matematica riduce solitamente il problema originario alla soluzione di un sistema di equazioni algebriche lineari. Quando si sceglie un algoritmo di soluzione, dobbiamo sapere se la matrice originale è non singolare? Inoltre, la questione della non degenerazione di una matrice è rilevante, ad esempio, nella teoria della convergenza di metodi iterativi, localizzazione di autovalori, nella stima di determinanti, radici di Apron, raggio spettrale, valori singolari di a matrice, ecc.
Si noti che una delle condizioni più semplici, ma estremamente utili per garantire la non degenerazione di una matrice è la ben nota proprietà della stretta dominanza diagonale (e riferimenti ad esse).
Teorema 1. Sia data una matrice A = e Cnxn tale che
s > r (a):= S k l, (1)
per ogni i e N:= (1,2,...n).
Allora la matrice A è non degenere.
Le matrici con proprietà (1) sono chiamate matrici a stretta dominanza diagonale
(matrici 8BB). La loro generalizzazione naturale è la classe di matrici a dominanza diagonale generalizzata (GBD), definita come segue:
Definizione 1. Una matrice A = [a^] e Cxn si dice matrice sBB se esiste una matrice diagonale non singolare W tale che AW sia una matrice 8BB.
Introduciamo diverse definizioni per la matrice
A \u003d [ay] e Spxp.
Definizione 2
(A) = eCn
si chiama matrice di confronto della matrice A.
Definizione 3. Matrice A = e C
\üj > 0, i = j
è una matrice M se
aj< 0, i * j,
tappetino inverso
matrice A">0, cioè tutti i suoi elementi sono positivi.
Ovviamente, anche le matrici della classe wBB sono matrici non singolari e possono esserlo
1Questo lavoro è stato parzialmente sostenuto dal Ministero dell'Istruzione e della Scienza della Serbia, sovvenzione 174019, e dal Ministero della Scienza e dello Sviluppo Tecnologico della Vojvodina, sovvenzioni 2675 e 01850.
trovato in letteratura sotto il nome di matrici H non degenerate. Possono essere definiti utilizzando la seguente condizione necessaria e sufficiente:
Teorema 2. La matrice A \u003d [ay ]e xi
matrice se e solo se la sua matrice di confronto è una matrice M non degenere.
Ormai sono già state studiate molte sottoclassi di matrici H non degenerate, ma tutte sono considerate dal punto di vista delle generalizzazioni della proprietà di dominanza strettamente diagonale (vedi anche riferimenti ivi).
In questo lavoro consideriamo la possibilità di andare oltre la classe delle matrici H generalizzando la classe SBB in modo diverso. L'idea principale è di continuare a utilizzare l'approccio di scaling, ma con matrici che non sono diagonali.
Considera la matrice A \u003d [ay ] e spxn e l'indice
Introduciamo la matrice
r (A):= £ a R (A):= £
ßk (A) := £ e yk (A) := aü - ^
È facile verificare che gli elementi della matrice bk Abk hanno la seguente forma:
ßk (LA), Y k (LA), akj,
i=j=k, i=j*k,
io = k, j * k, io * k, j = k,
Un inöaeüiüö neo^äyö.
Se applichiamo il Teorema 1 alla matrice bk Abk1 sopra descritta e alla sua trasposta, otteniamo due teoremi principali.
Teorema 3. Sia data una matrice qualsiasi
A \u003d [ay ] e spxn con elementi diagonali diversi da zero. Se esiste k e N tale che > Rk (A), e per ogni i e N \ (k),
allora la matrice A è non degenere.
Teorema 4. Sia data una matrice qualsiasi
A \u003d [ay ] e spxn con elementi diagonali diversi da zero. Se esiste k e N tale che > Jk (A), e per ogni i e N \ (k),
Allora la matrice A è non degenere. Sorge spontanea una domanda sulla relazione tra
matrici dei due teoremi precedenti: L^ - BOO -matrici ( definito dalla formula(5)) e
bk - Matrici BOO (definite dalla formula (6)) e la classe delle matrici H. Il seguente semplice esempio lo chiarisce.
Esempio. Consideriamo le seguenti 4 matrici:
e consideriamo una matrice bk Abk, k e N, simile all'originale A. Troviamo le condizioni in cui questa matrice avrà la proprietà di una matrice SDD (per righe o per colonne).
In tutto l'articolo, per r,k eN:= (1,2,.../?) useremo la notazione:
2 2 1 1 3 -1 1 1 1
" 2 11 -1 2 1 1 2 3
2 1 1 1 2 -1 1 1 5
Teoremi sulla non degenerazione
Tutti loro sono non degenerati:
A1 è b - BOO, nonostante non sia bk - BOO per ogni k = (1,2,3). Inoltre non è una matrice H, poiché (A^1 non è non negativo;
A2, per simmetria, è simultaneamente LH - BOO e L<2 - БОО, так же как ЬЯ - БОО и
b<3 - БОО, но не является Н-матрицей, так как (А2) вырожденная;
A3 è b9 - BOO, ma nessuno dei due
Lr è un SDD (per k = (1,2,3)), né una matrice H poiché (A3 ^ è anche degenere;
A4 è una matrice H poiché (A^ è non singolare e ^A4) 1 > 0, sebbene non sia né LR - SDD né Lk - SDD per qualsiasi k = (1,2,3).
La figura mostra la relazione generale tra
Lr - SDD , Lk - SDD e H-matrici insieme alle matrici dell'esempio precedente.
Comunicazione tra lR - SDD, lC - SDD e
diavolo min(|au - r (A)|) "
A cominciare dalla disuguaglianza
e applicando questo risultato alla matrice bk ab ^, si ottiene
Teorema 5. Sia data una matrice arbitraria A = [a--] e Cxn con elementi diagonali diversi da zero.
poliziotti. Se A appartiene alla classe - BOO, allora
1 + massimo^ i*k \acc\
Matrici H
È interessante notare che sebbene abbiamo
la classe delle matrici LC BOO applicando il Teorema 1 alla matrice ottenuta trasponendo la matrice LC AL^1, questa classe non coincide con la classe ottenuta applicando il Teorema 2 alla matrice Am.
Introduciamo le definizioni.
Definizione 4. La matrice A è chiamata ( bk -boo per righe) se AT ( bk -boo ).
Definizione 5. La matrice A è chiamata ( bsk -boo per righe) se AT ( bsk -boo ).
Gli esempi mostrano che le classi W - BOO,
bc-boo, (bk-boo per riga) e (b^-boo per riga) sono correlati tra loro. Pertanto, abbiamo esteso la classe delle matrici H in quattro modi diversi.
Applicazione di nuovi teoremi
Illustriamo l'utilità dei nuovi risultati nella stima della C-norma di una matrice inversa.
Per una matrice A arbitraria con stretta dominanza diagonale, il noto teorema di Varah (Varah) fornisce la stima
min[|pf(A)| - mk (LA), min(|yk (LA)| - qk(LA) - |af (LA)|)]" i i (Фf ii ii
Analogamente si ottiene il seguente risultato per le matrici Lk - SDD per colonne.
Teorema 6. Sia data una matrice arbitraria A = e xi con elementi diagonali diversi da zero. Se A appartiene alla classe bk -SDD per colonne, allora
Ik-lll<_ie#|akk|_
" "mln[|pf(A)| - Rf (AT), mln(|уk (A)|- qk (AT)- |aft |)]"
L'importanza di questo risultato sta nel fatto che per molte sottoclassi di matrici H non singolari esistono restrizioni di questo tipo, ma per quelle matrici non singolari che non sono matrici H, questo è un problema non banale. Pertanto, restrizioni di questo tipo, come nel teorema precedente, sono molto richieste.
Letteratura
Levy L. Sur le possibilité du l'equlibre electrique C. R. Acad. Paris, 1881. Vol. 93. P. 706-708.
Horn RA, Johnson CR analisi matriciale. Cambridge, 1994. Varga R.S. Gersgorin e i suoi circoli // Springer Series in Computational Mathematics. 2004 vol. 36.226 pag. Berman A., Plemons R.J. Matrici non negative nelle scienze matematiche. Classici della serie SIAM in matematica applicata. 1994 vol. 9. 340 rubli
Cvetkovic Lj. Teoria della matrice H vs. localizzazione di autovalori // Numer. Algor. 2006 vol. 42. Pag. 229-245. Cvetkovic Lj., Kostic V., Kovacevic M., Szulc T. Ulteriori risultati sulle matrici H e sui loro complementi di Schur // Appl. Matematica. Calcola. 1982. P. 506-510.
Varah J.M. Un limite inferiore per il valore più piccolo di una matrice // Linear Algebra Appl. 1975 vol. 11. Pag. 3-5.
Ricevuto dall'editore
Definizione.
Chiamiamo sistema un sistema con dominanza diagonale di riga se gli elementi della matricesoddisfa le disuguaglianze:
 ,
,

Le disuguaglianze significano che in ogni riga della matrice  si evidenzia l'elemento diagonale: il suo modulo è maggiore della somma dei moduli di tutti gli altri elementi della stessa riga.
si evidenzia l'elemento diagonale: il suo modulo è maggiore della somma dei moduli di tutti gli altri elementi della stessa riga.
Teorema
Un sistema con dominanza diagonale è sempre risolvibile e, inoltre, unico.
Considera il corrispondente sistema omogeneo:
 ,
,

Supponiamo che abbia una soluzione non banale  , Sia la componente di questa soluzione, che ha il modulo più grande, corrispondere all'indice
, Sia la componente di questa soluzione, che ha il modulo più grande, corrispondere all'indice  , cioè.
, cioè.
 ,
, ,
,
 .
.
Scriviamo  esima equazione del sistema nella forma
esima equazione del sistema nella forma

e prendi il modulo di entrambi i membri di questa uguaglianza. Di conseguenza, otteniamo:
 .
.
Ridurre la disuguaglianza di un fattore  , che, secondo, non è uguale a zero, arriviamo a una contraddizione con la disuguaglianza che esprime dominanza diagonale. La contraddizione che ne risulta ci permette di affermare coerentemente tre affermazioni:
, che, secondo, non è uguale a zero, arriviamo a una contraddizione con la disuguaglianza che esprime dominanza diagonale. La contraddizione che ne risulta ci permette di affermare coerentemente tre affermazioni:

L'ultimo di essi significa che la dimostrazione del teorema è completa.
Sistemi a matrice tridiagonale. Metodo di spazzata.
Quando si risolvono molti problemi, si ha a che fare con sistemi di equazioni lineari della forma:
, ,
,
 ,
, ,
,
dove coefficienti  , lati destro
, lati destro 
 noto insieme ai numeri
noto insieme ai numeri  e
e  . Le relazioni aggiuntive sono spesso chiamate condizioni al contorno per il sistema. In molti casi, possono avere un aspetto più complesso. Per esempio:
. Le relazioni aggiuntive sono spesso chiamate condizioni al contorno per il sistema. In molti casi, possono avere un aspetto più complesso. Per esempio:
 ;
;
 ,
,
dove  sono dati i numeri. Tuttavia, per non complicare la presentazione, ci limitiamo alla forma più semplice di condizioni aggiuntive.
sono dati i numeri. Tuttavia, per non complicare la presentazione, ci limitiamo alla forma più semplice di condizioni aggiuntive.
Approfittando del fatto che i valori  e
e  dato, riscriviamo il sistema nella forma:
dato, riscriviamo il sistema nella forma:

La matrice di questo sistema ha una struttura tridiagonale:

Ciò semplifica notevolmente la soluzione del sistema grazie a un metodo speciale chiamato metodo sweep.
Il metodo si basa sul presupposto che le incognite desiderate  e
e  legati dalla relazione di ricorrenza
legati dalla relazione di ricorrenza
 ,
, .
.
Qui le quantità  ,
, , detti coefficienti di sweep, devono essere determinati in base alle condizioni del problema, . Tale procedura, infatti, significa sostituire la definizione diretta delle incognite
, detti coefficienti di sweep, devono essere determinati in base alle condizioni del problema, . Tale procedura, infatti, significa sostituire la definizione diretta delle incognite  il compito di determinare i coefficienti di sweep con il successivo calcolo delle grandezze
il compito di determinare i coefficienti di sweep con il successivo calcolo delle grandezze  .
.
Per implementare il programma descritto, esprimiamo utilizzando la relazione  attraverso
attraverso  :
:
e sostituire  e
e  , espresso attraverso
, espresso attraverso  , nelle equazioni originali. Di conseguenza, otteniamo:
, nelle equazioni originali. Di conseguenza, otteniamo:
 .
.
Le ultime relazioni saranno certamente soddisfatte e, inoltre, indipendentemente dalla soluzione, se è richiesto che a  si sono verificate le uguaglianze:
si sono verificate le uguaglianze:

Da qui seguono le relazioni ricorsive per i coefficienti di sweep:
 ,
, ,
, .
.
Condizione al contorno sinistro  e rapporto
e rapporto  sono consistenti se poniamo
sono consistenti se poniamo
 .
.
Altri valori dei coefficienti di sweep  e
e  troviamo da, con cui e completiamo la fase di calcolo dei coefficienti di sweep.
troviamo da, con cui e completiamo la fase di calcolo dei coefficienti di sweep.
 .
.
Da qui puoi trovare il resto delle incognite  nel processo di scansione all'indietro utilizzando una formula ricorsiva.
nel processo di scansione all'indietro utilizzando una formula ricorsiva.
Il numero di operazioni necessarie per risolvere un sistema generale utilizzando il metodo gaussiano aumenta con l'aumentare  proporzionalmente
proporzionalmente  . Il metodo di sweep è ridotto a due cicli: prima si calcolano i coefficienti di sweep utilizzando le formule, quindi, utilizzandoli, si trovano i componenti della soluzione del sistema utilizzando le formule ricorrenti
. Il metodo di sweep è ridotto a due cicli: prima si calcolano i coefficienti di sweep utilizzando le formule, quindi, utilizzandoli, si trovano i componenti della soluzione del sistema utilizzando le formule ricorrenti  . Ciò significa che all'aumentare delle dimensioni del sistema, il numero di operazioni aritmetiche crescerà proporzionalmente
. Ciò significa che all'aumentare delle dimensioni del sistema, il numero di operazioni aritmetiche crescerà proporzionalmente  , ma no
, ma no  . Pertanto, il metodo sweep nell'ambito della sua possibile applicazione è significativamente più economico. A ciò va aggiunta la particolare semplicità della sua implementazione software su un computer.
. Pertanto, il metodo sweep nell'ambito della sua possibile applicazione è significativamente più economico. A ciò va aggiunta la particolare semplicità della sua implementazione software su un computer.
In molti problemi applicati che portano a SLAE con una matrice tridiagonale, i suoi coefficienti soddisfano le disuguaglianze:
 ,
,
che esprimono la proprietà della dominanza diagonale. In particolare, incontreremo tali sistemi nel terzo e nel quinto capitolo.
Secondo il teorema della sezione precedente, la soluzione di tali sistemi esiste sempre ed è unica. Hanno anche un'affermazione importante per il calcolo effettivo della soluzione usando il metodo sweep.
Lemma
Se per un sistema con matrice tridiagonale è soddisfatta la condizione di dominanza diagonale, allora i coefficienti di sweep soddisfano le disuguaglianze:
 .
.
Svolgiamo la dimostrazione per induzione. Secondo  , io mangio
, io mangio  l'affermazione del lemma è vera. Supponiamo ora che sia vero per
l'affermazione del lemma è vera. Supponiamo ora che sia vero per  e considera
e considera  :
:
 .
.
Quindi l'induzione da  a
a  giustificato, che completa la dimostrazione del lemma.
giustificato, che completa la dimostrazione del lemma.
Disuguaglianza per i coefficienti di sweep  rende la corsa stabile. Supponiamo infatti che la componente di soluzione
rende la corsa stabile. Supponiamo infatti che la componente di soluzione  come risultato della procedura di arrotondamento viene calcolato con qualche errore. Quindi quando si calcola il componente successivo
come risultato della procedura di arrotondamento viene calcolato con qualche errore. Quindi quando si calcola il componente successivo  secondo la formula ricorsiva, questo errore, dovuto alla disuguaglianza, non aumenterà.
secondo la formula ricorsiva, questo errore, dovuto alla disuguaglianza, non aumenterà.
e almeno una disuguaglianza è stretta. Se tutte le disuguaglianze sono rigorose, si dice che la matrice lo sia ha severa dominanza diagonale.
Le matrici con dominanza diagonale appaiono abbastanza spesso nelle applicazioni. Il loro vantaggio principale è che i metodi iterativi per risolvere SLAE con una tale matrice (il metodo di iterazione semplice, il metodo Seidel) convergono a una soluzione esatta che esiste ed è unica per ogni lato destro.
Proprietà
- Una matrice con stretta dominanza diagonale è non degenerata.
Guarda anche
Scrivi una recensione sull'articolo "Dominanza diagonale"
Un estratto che caratterizza la predominanza diagonale
Il reggimento ussaro di Pavlograd era di stanza a due miglia da Braunau. Lo squadrone, in cui Nikolai Rostov prestava servizio come cadetto, si trovava nel villaggio tedesco di Salzenek. Al comandante dello squadrone, il capitano Denisov, noto all'intera divisione di cavalleria con il nome di Vaska Denisov, fu assegnato il miglior appartamento del villaggio. Junker Rostov viveva con il comandante dello squadrone da quando aveva raggiunto il reggimento in Polonia.L'11 ottobre, proprio il giorno in cui tutto nell'appartamento principale si era rimesso in piedi alla notizia della sconfitta di Mack, la vita al campeggio presso il quartier generale della squadriglia continuò tranquillamente come prima. Denissov, che aveva perso tutta la notte a carte, non era ancora tornato a casa quando Rostov, la mattina presto, a cavallo, tornò dal foraggiamento. Rostov, in uniforme da cadetto, cavalcò fino al portico, spinse il cavallo, gli gettò via la gamba con un gesto flessibile e giovane, si alzò sulla staffa, come se non volesse separarsi dal cavallo, alla fine saltò giù e chiamò a il Messaggero.